Load test with Locust
I had a very nice experience doing some load analysis with locust :
- it has a docker image with a ready to use docker compose file
- you can script the load scenario with some
Pythonfiles - it features a web interface with dashboards.
# docker-compose.yml
version: '3'
services:
master:
image: locustio/locust
ports:
- "8089:8089"
volumes:
- ./:/mnt/locust
command: -f /mnt/locust/locustfile.py --master -H http://master:8089
worker:
image: locustio/locust
volumes:
- ./:/mnt/locust
command: -f /mnt/locust/locustfile.py --worker --master-host master
You need a locustfile.py in the same directory:
from locust import HttpUser, task
class HomeUser(HttpUser):
@task
def home(self):
self.client.get("/")
$ docker pull locustio/locust
$ docker-compose up --scale worker=4
When you open localhost:8089, you can then set the number of requests, and the host, and you get a curve like this one:
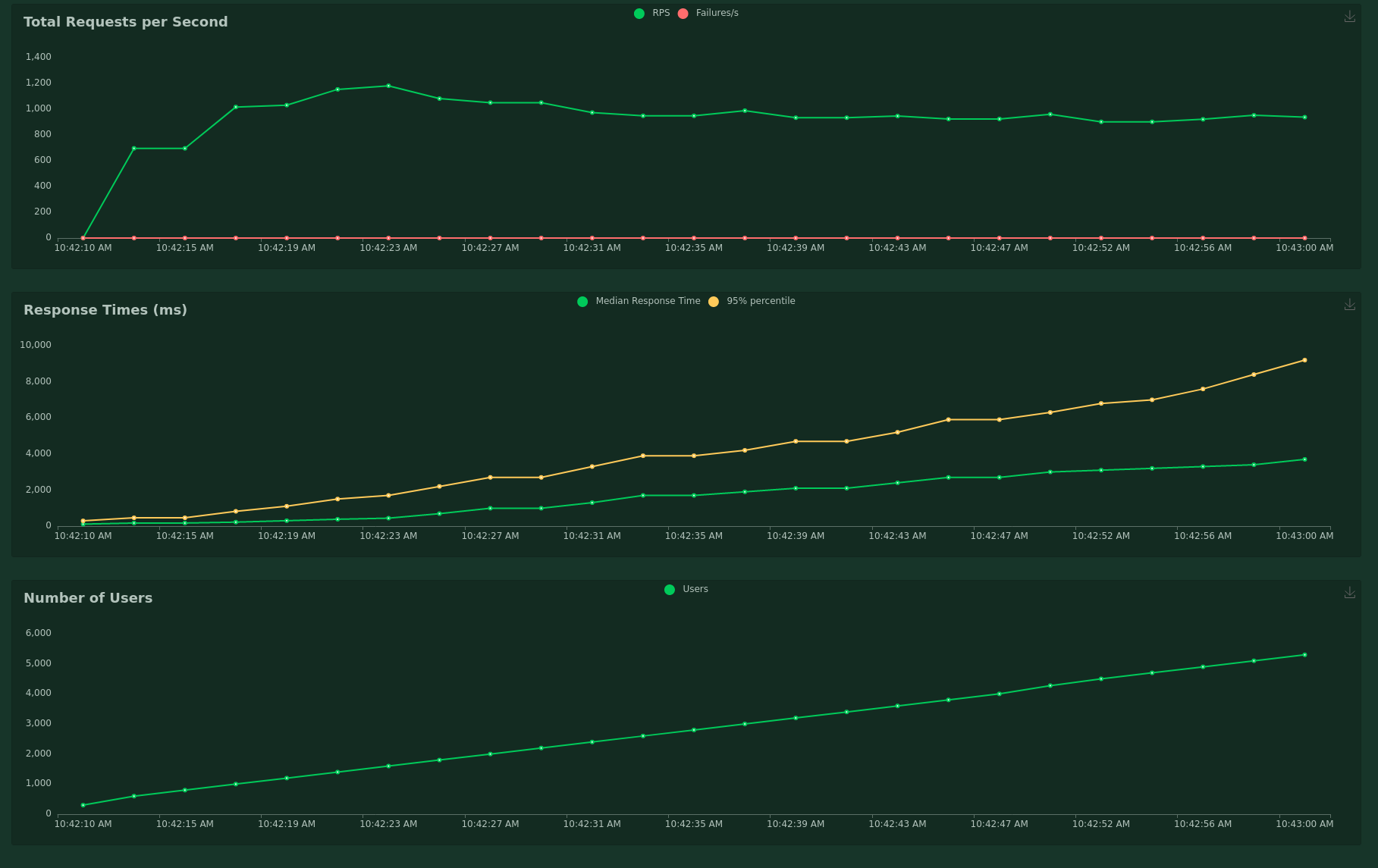
Conversely, I tried to do the same thing with tools like apache bench or siege.
- options with only short names are cryptic
- not having data as a time-serie made the interpretation harder
$ ab -k -n 1000 -c 100 https://some-website.fr/
This is ApacheBench, Version 2.3 <$Revision: 1843412 $>
Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/
Licensed to The Apache Software Foundation, http://www.apache.org/
Benchmarking some-website.fr (be patient).....done
Server Software: Apache
Server Hostname: some-website.fr
Server Port: 80
Document Path: /
Document Length: 173521 bytes
Concurrency Level: 100
Time taken for tests: 1.212 seconds
Complete requests: 100
Failed requests: 0
Keep-Alive requests: 100
Total transferred: 17422593 bytes
HTML transferred: 17352100 bytes
Requests per second: 82.51 [#/sec] (mean)
Time per request: 1211.973 [ms] (mean)
Time per request: 12.120 [ms] (mean, across all concurrent requests)
Transfer rate: 14038.47 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 32 41 1.6 41 42
Processing: 170 526 171.9 596 1090
Waiting: 38 58 9.2 59 77
Total: 207 567 172.0 637 1131
Percentage of the requests served within a certain time (ms)
50% 637
66% 670
75% 680
80% 690
90% 725
95% 837
98% 1089
99% 1131
100% 1131 (longest request)