Making a chess OCR with python, opencv and deeplearning techniques
If you want to get better at chess, one of the #1 recommendation everywhere is to play a lot of chess tactics problems. You can play some problems on lichess, but I wanted a more structured approach. I bought a few copies of chess tactics books. The problem is that solving them on paper has many issues:
- it is boring : when you can’t find a solution, you have to go through many pages in order to lookup the solution.
- keeping a database of my ability (speed) to solve the problems is complicated
- the problems look ugly.
I have found a PDF copy of some chess books, and I decided to (attempt to) make a digital version of those problems : instead of images, I want to make a database using the Forsyth–Edwards Notation for those chessboards. It’s a one line representation of a board with all the information we need, most importantly the location of the pieces and whose turn it is to play. With this representation, we can do some fun things, like making a higher definition of the problem, or solving them with a chess engine.
In one image that does not make justice to how much work was involved, we will do this:
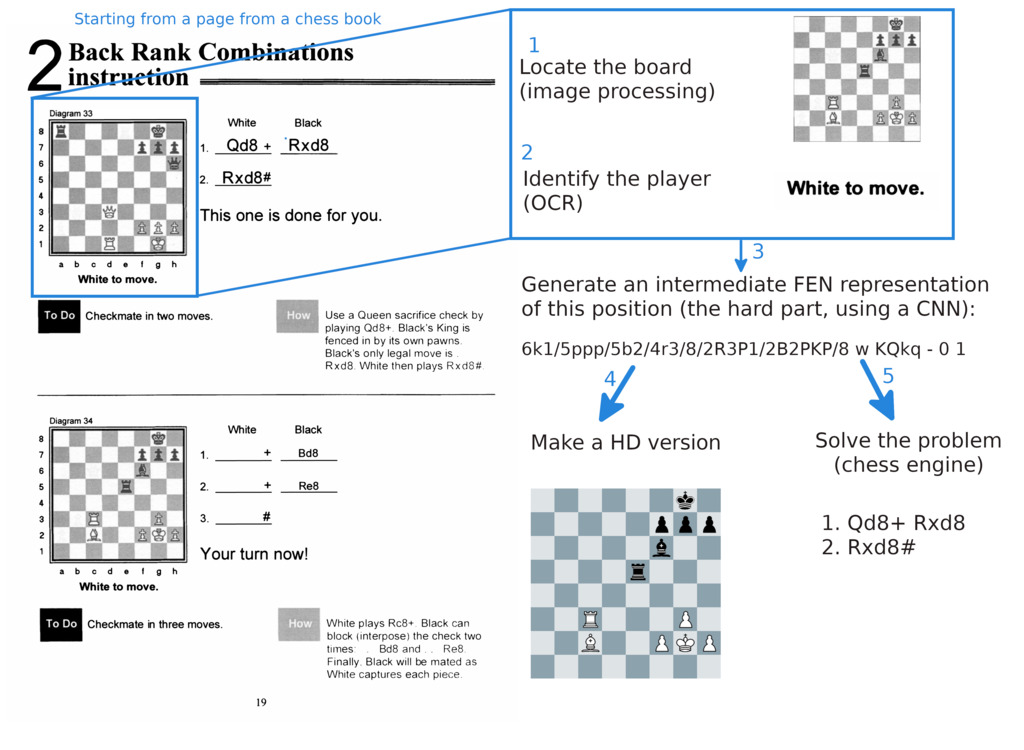
This article will talk about the algorithms I used, and more broadly about the complete data pipeline in order to extract data, create a reliable machine learning process, create a suitable representation for the chess problems, and finding the solutions for the chess problems. This is definitely not an industry-ready pipeline, but you’ll find similar ideas with more professional tools in the data processing industry. I’ll only show interesting portions of the code. The actual project deals with many mundane things like directories, edge cases, error handling… but we’ll skip those.
Why?
Why not ? It’s fun to do. This project is about learning and solving a real-world image-processing and data-science project.
What about copyright?
I’m not doing this in order to release an illegal digital copy of the books, and I’ll keep the results for myself. If you are looking for a large database of chess problems with a permissive license, ask lichess.
TL;DR / our pipeline
We will start from scratch from a PDF book, so there’s a lot of work in order to prepare things and then get to where we want. Broadly speaking, we need to prepare our data, train and use a model, then do something with the output.
1) Preparing the data
Most data science project involve data preparation in some way, and this project is no exception. That’s actually often the most time-consuming part.
- Extract PNG pages from the PDF
- Extract each problem (and optionnally sort them by chapter)
- Identify the player - we will use an OCR
- Extract the chess board from the problem page
- Extract the cells from the chess boards
- Prepare the training set - we will sort the boards’ cells by type of piece and background
2) The learning pipeline
That’s probably what you are here for so don’t be afraid to skip the first part.
- Training a network - we will use a CNN (convolutional neural network) in order to identify the content of the cell
- Classification - we will have a database of problems using the FEN notation
- Checking the results - we will check and fix the incorrect boards manually
3) Cool stuff with the results (lots of FEN boards)
- Generating nicer problems
- Finding the solutions of the problems − we will feed the problems to a game engine
- Generate an Anki deck − one option for all of this is to download those patterns into your memory
Extract the relevant pages from the book
So, we have a PDF book, and we need images in order to perform image processing on them. We’ll make a bash script that will use convert, a tool from the imagick suite, in order to extract each page as a PNG. Note that we only extract the pages we need, and that we make large image (300dpi, 2048x2048 pixels, on a white background).
for i in {17..238}
do
convert -background white -flatten -alpha off \
-density 300 -antialias "input/book.pdf[$i]" \
-resize 2048x -quality 100 "data/pages/page-%03d.png"
done
When we do so, we should have all the pages stored in the correct directory:
$ tree data/pages/
data/pages/
├── page-017.png
├── page-015.png
…
└── page-238.png
Here is an example of such a page:

Then, we need to extract the problems by chapters
That’s not mandatory for classification but with large enough datasets it’s way easier to have things correctly organised.
Structure of each chapter
We have the pages as PNGs, and we now need to extract the chess problems from those images.
The book has 14 chapters, and we want all the problems for these different chapters to be stored in the correct directory. Each problem id in the image file should match the ids in the book. We want something like that:
chapters
├── chapter-01
│ ├── problem-002.png
│ ├── problem-003.png
│ ├── …
│ ├── problem-030.png
│ └── problem-031.png
├── chapter-02
…
├── chapter-13
└── chapter-14
In order to do so, the simplest way I’ve found is to curate some data by hand from the book, using the table of content. We will make a CSV with each chapter id, title, start and end pages, and the first problem id.
That’s a bit overkill and it’s a manual task, but that’s 15mn work that’s going to save us a lot of debug later on, and things will in a nice location. Most chess tactics problem books I’ve used have less than 20 chapters, so that’s acceptable.
chapter_number,title,start_page,end_page,first_problem_id
1,Pins,2,17,1
2,Back rank combinations,18,33,32
3,Knight forks,34,49,63
4,Forks and double attacks,50,65,94
5,Discovered checks,66,81,125
6,Double checks,82,97,156
7,Discovered attacks,98,113,187
8,Skewers,114,129,218
9,Double threats,130,145,249
10,Promoting pawns,146,161,280
11,Removing the guard,162,177,311
12,Perpetual check,178,193,342
13,Zugzwang/stalemates,194,209,373
14,Identify tactics,210,225,404
The book and the PDF are indexed differently. Now we simply need to keep in mind that the page 2 from the table of content is actually the page 14 of the PDF.
Then, we need to be able to retrieve these data from the code:
# extract-boards-by-chapter.py
import csv
def load_chapters(chapter_file:str="chapters.csv") -> dict:
chapters = {}
with open(chapter_file, 'r') as csvfile:
fieldnames = ["chapter_number","title","start_page","end_page","first_problem_id"]
csvreader = csv.DictReader(csvfile, fieldnames=fieldnames)
next(csvreader, None) # skip header
for row in csvreader:
chapters[int(row['chapter_number'])] = {
"title": row['title'],
"start_page": int(row['start_page']),
"end_page": int(row['end_page']),
"first_problem_id": int(row['first_problem_id']),
}
return chapters
chapters = load_chapters()
pp.pprint(chapters)
Extracting the actual chess problems
Depending on the book, there can be many problems per page. We won’t extract the chess boards right away: We want to extract the chess problem broadly at first, in order to reduce the visual noise while keeping the useful information. At the end of this step, we’ll have a lot of images like this:

This step also accelerates the debug. There are 2 problems per page, so we simply extract 2 large areas and save them as a file.
def extract_problem_by_bounds(image, bounds:list, chapter_id:int, problem_id:int):
(x0, y0, x1, y1) = bounds
cropped_img = image[y0:y1, x0:x1]
cv2.imwrite(problem_file(chapter_id, problem_id), cropped_img)
def extract_chapter(chapter_id:int, first_page:int, last_page:int, first_problem_id:int):
top_problem_coords = (80,330), (750,1080)
bottom_problem_coords = (80,1550), (750,2300)
problem_id = first_problem_id+1
# All the pages but the first of a chapter have 2 chess problems per page
for page_number in range (first_page+1, last_page+1):
img = load_page_image(page_number)
if img is not None:
(x0, y0), (x1, y1) = top_problem_coords
extract_problem_by_bounds(img, [x0, y0, x1, y1], chapter_id, problem_id)
(x0, y0), (x1, y1) = bottom_problem_coords
extract_problem_by_bounds(img, [x0, y0, x1, y1], chapter_id, problem_id+1)
problem_id += 2
Now we need to do 2 things using those images:
- extract the actual chess board from the image. Remember, the ultimate goal is to recognize the content of the cells.
- find whose turn it is to play
Finding who has to play
Who should play is a very important information that can change the face of the problem ; we can’t simply say it’s white turn to play. So we need to find this information, which is often textual.
Here I used an OCR, easyocr (pip install easyocr), through a modification of the code from this article : we’ll search for the text in the problem image. Since we reduced the problem space by extracting the chess boards from the pages, it can be only one for “White to play” or “Black to play”.
The OCR won’t necessary find the exact sentence though. Sometimes we’ll have 2 strings, “White” and “to play”, sometimes 3… it doesn’t mattern much: it’s quite fast, and we only care about whether there is “black” or “white”. We make a CSV that stores the pair (problem id, turn to play).
from easyocr import Reader
import os, csv
import cv2
def cleanup_text(text:str) -> str:
# strip out non-ASCII text so we can draw the text on the image
# using OpenCV
return "".join([c if ord(c) < 128 else "" for c in text]).strip()
def search_turn_to_play(image):
global reader
# We only search for the text in the bottom of the image
crop_img = image[600:, 0:]
results = reader.readtext(crop_img)
# loop over the results
for (bbox, text, prob) in results:
text = cleanup_text(text).lower()
if "black" in text or "white" in text:
return text
return None
if __name__ == "__main__":
reader = Reader(["en"], gpu=False)
chapters = load_chapters()
fieldnames = ['problem', 'turn']
with open("{}/turns.csv".format(RESULTS_ROOT_DIRECTORY), "w") as csv_file:
csvwriter = csv.DictWriter(csv_file, fieldnames=fieldnames)
csvwriter.writeheader()
chapter_ids = list(chapters.keys())
for chapter_id in chapter_ids:
curr_chapter = chapters[chapter_id]
for problem_number in all_problems_in_chapter(curr_chapter):
image = cv2.imread(problem_file(chapter_id, problem_number))
turn_to_play = search_turn_to_play(image)
print(chapter_id, problem_number, turn_to_play)
csvwriter.writerow({ 'problem': problem_number, 'turn': turn_to_play })
csv_file.flush()
It creates a large CSV file, mostly full with accurate results. In some instances there were a couple issues that were easy to fix by hand:
problem,turn
…
30,white to move.
31,white to move.
32,
33,white to move.
34,white to move.
Extracting the chess boards
So we have an image that contains, somewhere, a chess board, and we want to extract this chess problem as an image.
Ok, the actual image processing starts now. As we’ll see, it’s quite simple:
- we extract the contours of the image
- we pick one with a plausible area
- we save this as an image. done !
At the end of this step, we have filled a directories with low quality images like this:

import cv2
from utils import *
def extract_board(chapter_id, problem_id):
"""
We use the contours in order to locate the board. We know its area, which is roughly always the same
"""
img = load_image(problem_file(chapter_id, problem_id))
ret,thresh = cv2.threshold(img,127,255,0)
contours, hierarchy = cv2.findContours(thresh,cv2.RETR_TREE,cv2.CHAIN_APPROX_SIMPLE)
index = 0
height, width = img.shape[:2]
for c in contours:
(x, y, w, h) = cv2.boundingRect(c)
if ((w >= 500 and w < 530) and (h > 500 and h < 530)) or ((w >= 975 and w < 1025) and (h >= 975 and h < 1025)) :
crop_img = img[y:y+h, x:x+w]
cv2.imwrite(board_file(problem_id), crop_img)
Depending on the quality of the scans, you may need to remove the curvature by applying a transformation on the chess board. I did without this, but this could be an improvement.
Extracting the cells, and preparing the training set
So now we have many chess boards. We roughly cut the board image in 8x8 cells, and save the cells as individual 65x65 pixels images:
def extract_cell_from_board(img, i, j, image_size):
"""Returns the square cell (i, j) from the board img, with dimensions (image_size, image_size)"""
x = i*image_size
y = j*image_size
crop_img = img[y:y+image_size, x:x+image_size]
return crop_img
def extract_cells_from_image(chapter_id, problem_id, image_size):
"""Extracts the 64 cells of a chess board, and store them as separate images"""
img = load_image(board_file(problem_id))
chapter_directory = raw_cell_directory(chapter_id)
if img is not None:
for (i, j) in product(range(0, 8), range(0, 8)):
index = j * image_size + i
cropped_img = extract_cell_from_board(img, i, j, image_size)
cv2.imwrite('{}/problem-{}-{}.png'.format(chapter_directory, str(problem_id).zfill(3), index), cropped_img)
Now we have a lot of images like this:




A lot = 64 cells per problem x number of problems in book.
Then, we’ll need to manually go through those cells, and copy the images in dedicated directories. I kept the FEN nomenclature, and separated the images depending on their background. So Rw means “white rooks on white background”, while “Rb” is “white rooks on black background”.
tree input/training-with-bgs/ -d 2
input/training-with-bgs/
├── bb
├── Bb
├── bw
├── Bw
├── e
├── E
├── kb
├── Kb
├── kw
├── Kw
├── nb
├── Nb
├── nw
├── Nw
├── pb
├── Pb
├── pw
├── Pw
├── qb
├── Qb
├── qw
├── Qw
├── rb
├── Rb
├── rw
└── Rw
Here is the content of the Rw directory:
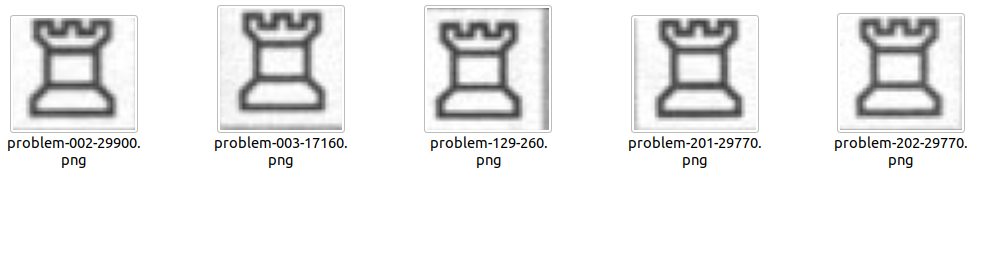
This is veeeeery tedious to do, and it can be error prone (putting images in the incorrect directory happened, then the model was of course incorrect).
In a real-world data-science project you’ll want a more robust annotation tool like prodigy, but again, that’s a weekend project.
Identifying the chess problems
Now we have a way to tell “that’s what a white rook on white background look like”, but we want to identify the complete chess board.
We want to go through all the cells in the chess board, identify the content of those cells, put them on a chess board and return the FEN representation of said board. In pseudo-code, that’s something like this:
def find_board(img):
board = Board()
for i in range(0, 8):
for j in range(0, 8):
crop_img = extract_cell(img, i,j)
best_picture = find_best_match(crop_img)
if best_picture is not None:
board.board[j][i] = best_picture
return board.to_fen()
The big question is : what should we put in the find_best_match function ?
I have made a few tries at various algorithms for recognizing the cells. This is a hobby project, and me learning about image processing was as interesting as actually solving the problem:
- mean squared error
- SSIM
- template matching
- k-nearest neighbours neural network.
- convolutional neural networks, the state of the art for image classification.
Even though that was predictable, classic image processing methods didn’t fare well compared to neural network. kNN were promising: they are very fast and the error rate was low. However, one of the book I wanted to digitize had more than 5000 problems, and fixing the errors would take hours. So I went for something more solid:
- we will use a CNN, a convolutional neural network
- we need a training set: we just created one
Depending on your needs −real-time or not? will you train it yourself, or use the available weights ?− there are many models out there. I used a modification of VGGNet because it had very good results.
The actual code is not mine here ; I modified a classifier by Adrian Rosebrock of PyImageSearch (Adrian Rosebrock, OpenCV Face Recognition, PyImageSearch, Keras and Convolutional Neural Networks (CNNs), accessed in january 2021). You shoud check out its great work (I mean it ! There are so many great articles on image processing with opencv on his blog) ; my main loop is almost a copy paste of its classifier, except I classify 8x8 cells per board:
def find_board(img, problem_id, image_size):
global model
board = Board()
board.empty()
for i in range(0, 8):
for j in range(0, 8):
crop_img = extract_custom_cell_from_board(img, i, j)
crop_img = preprocess(crop_img)
label = predict(model, crop_img)
if label != 'e' and label != 'E':
# we plot the non empty labels
board.board[j][i] = label[0]
return board
def preprocess(image):
image = cv2.resize(image, (96, 96))
image = image.astype("float") / 255.0
image = img_to_array(image)
image = np.expand_dims(image, axis=0)
return image
def load_cnn_with_labels(model_file:str, label_binarizer:str):
model = load_model(model_file)
lb = pickle.loads(open(label_binarizer, "rb").read())
return model, lb
def extract_custom_cell_from_board(img, i, j):
"""Returns the square cell (i, j) from the board img"""
cell_height, cell_width = img.shape[0]//8, img.shape[1]//8
x = i*cell_width
y = j*cell_height
crop_img = img[y:y+cell_height, x:x+cell_width]
return crop_img
def predict(model, image):
proba = model.predict(image)[0]
idx = np.argmax(proba)
label = lb.classes_[idx]
return label
This got me thinking about why and how deep learning networks actually work at all. I’ve found the following links to be interesting:
- Why do convolutional network work ?
- What is Pooling in Deep Learning?
- What are the advantages of ReLu over sigmoid
I’m also currently reading Hands-on Machine Learning with Scikit-Learn, Keras, and TensorFlow which is awesome and I should have started with that.
Generating images after classification
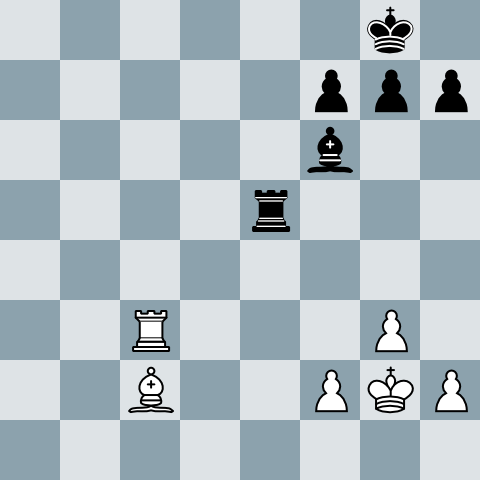
So now we have a csv file that contains the pairs (problem id, fen). We can generate better PNGs using fen2image, a tool I wrote a few years ago that take a FEN representation of a chess board an generates… an image.
import os, csv, argparse
if __name__ == "__main__":
ap = argparse.ArgumentParser()
ap.add_argument("-c", "--csv", required=True,
help="path to trained model model")
args = vars(ap.parse_args())
with open(args["csv"], 'r') as csvfile:
fieldnames = ['problem', 'fen']
csvreader = csv.DictReader(csvfile, fieldnames=fieldnames)
next(csvreader, None) # skip header
for row in csvreader:
print(row['fen'], row['problem'])
os.system("./fen2image -fen \"{}\" -output \"data/recognized/problem-{}.png\"".format(row['fen'], row['problem']))
And boom ! Now we have tons of images like this one.
Manual verification
Before automating, it’s nice to manually compare what we have and what we got. I made a quick and dirty tool that display the original images and next to it the images after classification.
It’s a short flask web application, that exposes the images and a index that we can browse.
I also linked to the position editor on lichess: when there were errors, I could fix the position manually and update the CSV file. The various algorithms had different results and they were not 100% perfect. Thanks to this, I could quickly build a ground truth database, that helped me evaluate the quality of the result.
import os, csv, argparse
from flask import Flask, render_template, redirect, url_for, request
from flask import send_from_directory
app = Flask(__name__)
@app.route('/', methods=['GET'])
def home():
global args
problems_metadata = {}
with open(args["csv"], 'r') as csvfile:
fieldnames = ['problem', 'fen']
csvreader = csv.DictReader(csvfile, fieldnames=fieldnames)
next(csvreader, None) # skip header
for row in csvreader:
problems_metadata[int(row['problem'])] = row['fen']
return render_template('home.html', problems = problems_metadata.keys(), metadata = problems_metadata)
@app.route('/boards/<path:path>', methods=['GET'])
def serve_boards(path):
problem_file_dir = os.path.join(os.path.dirname(os.path.realpath(__file__)), 'data/boards-only')
if not os.path.isfile(os.path.join(problem_file_dir, path)):
path = os.path.join(path, 'index.html')
return send_from_directory(problem_file_dir, path)
@app.route('/recognized/<path:path>', methods=['GET'])
def serve_recognized(path):
recognize_file_dir = os.path.join(os.path.dirname(os.path.realpath(__file__)), 'data/recognized')
if not os.path.isfile(os.path.join(recognize_file_dir, path)):
path = os.path.join(path, 'index.html')
return send_from_directory(recognize_file_dir, path)
if __name__ == "__main__":
ap = argparse.ArgumentParser()
ap.add_argument("-c", "--csv", required=True, help="path csv file with the problems")
args = vars(ap.parse_args())
app.run(host='0.0.0.0',port=8080)
Quick and dirty I said, but it got the job done.
Solving the chess problems
I wanted to have the solutions of the chess problems, but I did not want to parse the solution pages. They are usually messy, with icons for the pieces, sometimes text annotations and multiple variations… Their layout vary widely, so I did not want to write a custom parser for each book.
A quick way to bypass this problem is to use a chess engine like stockfish (the state of the art for algorithmic AI in chess): we can communicate with most chess engines using the UCI protocol, and stockfish obviously speaks UCI.
python-chess wraps this protocol for us, so all we have to do is to feed it with a FEN problem and ask for the solution. In this example, we know that the solution is a mate in 1, 2 or 3 so we ask stockfish for the best moves. When the solution has more move than expected, an error occured somewhere : sometimes it is in the book, but most of the time it is in our classification.
def search_best_move(i, fen, max_thinking_time=0.1):
board = chess.Board()
board.set_fen(fen)
# https://stackoverflow.com/questions/58630739/python-stockfish-is-opening-too-many-processes#comment103568889_58630739
with chess.engine.SimpleEngine.popen_uci("/usr/games/stockfish") as engine:
pgn = chess.pgn.Game()
pgn.setup(board)
moves = []
latest = pgn
while not board.is_game_over():
try:
result = engine.play(board, chess.engine.Limit(time=max_thinking_time))
board.push(result.move)
moves.append(result.move)
latest = latest.add_variation(result.move)
if len(moves) > expected_length(i):
if DEBUG:
print("solving problem {} is too long".format(i))
return None, []
except:
if DEBUG:
print("{} breaks the chess engine".format(i))
return None, []
engine.quit()
if len(pgn.variations) > 0:
# We dont want the whole PGN with header, we only want the main variation that leads to checkmate
return (pgn.variations[0], moves)
else:
return None, []
def expected_length(problem_id):
# Problems 1 to =306: mate in 1
# Problems 307 to =3718: mate in 2
# Problems 3718 to =4462: mate in 3
if 1 <= problem_id <= 306:
return 1
elif 307 <= problem_id <= 3718:
return 3
elif 3719 <= problem_id <= 4462:
return 5
else:
raise Exception("unexpected problem id")
problems_metadata = read_fens(args["boards"])
nb_errors = 0
for i in problems_metadata.keys():
if i in problems_metadata:
fen = problems_metadata[i]["fen"]
variation, moves = search_best_move(i, fen, float(args["max_thinking_time"]))
if variation is not None:
if len(moves) == expected_length(i):
print("{},{},{}".format(i, fen, variation))
else:
nb_errors += 1
if DEBUG:
print("problem {} has unexpected length".format(i))
else:
if DEBUG:
print("no problem {}".format(i))
Generating a anki deck
Anki is a spaced repetition system which is useful and efficient for rote memorization, which is one of the possible end goal of this project.
We have the problems as pretty images and their solutions, so we can build an anki deck in order to try to memorize them. At its core, we need a loop like this (with carefully placed images in Anki’s directory) in order to generate a CSV file that Anki can import:
for chapter_id in chapter_ids:
curr_chapter = chapters[chapter_id]
# print(curr_chapter)
for problem_id in all_problems_in_chapter(curr_chapter):
page = find_solution_page(problem_id)
print('<img src="{}">;<img src="data/solutions/page-{}.png">'.format(problem_file(chapter_id, problem_id), page))
Conclusion
Well, that was quite a project !
- We did some image processing with opencv (contours, image conversion, various metrics)
- we used an OCR
- we played with various image processing algorithms and settled for an open source implementation of a convolutional neural network.
- We used tools I wrote years ago, and put everything together in an Anki deck in order to attempt to get better at chess through spaced-repetition.
- woops, we didn’t play a single game in the process ;)