Better odds against my 3-year-old kids at its favorite game

My 3-year-old kid has become a huge, huge fan of his card game “Ballons.” We’ve been playing many games every day during the last three months. The game is straightforward, so after a while, I had to find something to fuel some interest in playing with him. What about finding a better strategy than him? To do so, we will study the game’s properties and write many Monte Carlo simulations.
The game
Ballons is a 2-4 players card game.
These are the rules of the game:
- Deal every player 5 balloons.
- Each player then pick action cards, one after each other:
- “pop a balloon of color x” (4 such cards for each color, there are 5 colors)
- “adult/parent: recover a balloon of your choice, if possible” (5 such cards)
- When you run out of cards in the action deck, you shuffle the discarded cards and keep playing.
- A player has lost when all his balloons popped
That’s it. The ratings often say “it’s a great first game for small kids, but it quickly becomes boring for everybody.”
Initial state of the game

The game after a few action cards

Our goal
There were many, but let’s see:
- how long are the games?
- what are the winning odds of my kid?
- can we improve those odds? If so, how much will we improve?
We will focus on two-player games because that’s easier to visualize, and because we only play this.
To answer the last question, we need to model and answer the following question:
The only possible choice in this game happens when you can recover a balloon, and you popped more than one. How do you choose which balloon to recover?
A model for my kid’s play
My kid seems to choose randomly, so modeling its play was easy:
- when there is no choice, follow the flow of the game
- when there is a choice, pick randomly
Simulating games
I wrote a lot of rust and python code in order to find the answers to my questions. I implemented the rules of the game, then wrote various simulations in order to identify some numbers that we’ll see in this article. The 200 lines of the ballons library contains the game code. This library is then used in many simulations at the root of the project.
The simulations all are Monte Carlo based, which means, in short, “run as many games with random initial conditions as you can, then average the results.” Due to the simplicity of the game, standard Monte Carlo is enough.
Notes on performances
I did not need to write two implementations: it just happens that it was a fun project, and I got carried away with a never-ending stream of «just one more thing»: more speed, better algorithms, FFI, parallelization, and so on.
Monte Carlo is iterative. Accuracy in a Monte Carlo simulation converge with a square root law: in order to have one more digit accuracy (so a x10 improvement), you need 10^2 = 100 more iterations. So in order to have a good accuracy for enough digits, you need a lot of iterations, and powers of 100 grow quickly.
I ran between 10k and 49x10 millions simulations per program, which was a bit slow for certain configurations (~30mn) in Python. Using a faster language like Rust helped. Every simulation is independant: Monte Carlo can easily be parallelized, so in the end I took advantage of that as well.
Some properties of this game
What makes this game interesting to me is that it sounds easy to simulate and very limited:
- 2 player game (for this study; you can play with up to 5 players)
- Non-deterministic
- Unlimited game tree depth, but
- Low branching factor
- No interactions between players
Let’s see first what the game depth is, then we will estimate the branching factor.
Depth - how long the games are ?
That was my initial question: some games are very long. This is sometimes a complain in the reviews. In my experience, the perfect match requires no more than two deals of the action deck. Otherwise, my kid loses interest. He likes dealing cards and playing many games, not spending a lot of time during the actual game.
So I wrote a Monte Carlo simulation: I ran many random games with random hands, counted the length of the games, then plotted a bar chart of the results:
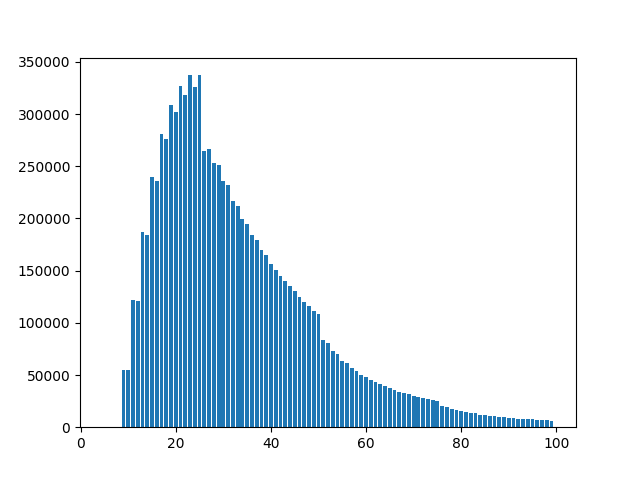
When you change the number of parent cards, the curve gets skewed towards shorter games. That’s quite intuitive, but that’s the first result that shows we can learn some stuff (the actual probabilities) with our code.
In my experience, the ideal number of parent card is 3 or 4. With 5, games tend to be too long; they are often very short with 1 or 2.
Let’s move on to some more fun stuff!
Branching factor
The branching factor counts, from a given state, to how many states we can go.
For us, the branching factor derives from the 25 action cards:

There are:
- 4 “pop” of each color
- 5 “recover”
The intuition is that the branching factor is low. How low?
We can find some bounds:
- it is >= 1: after every card, pop or recover, you’ll play a new card
- it is <= 4: if you pick a parent action card, you can at most choose between 4 cards which one to recover
Then, we can average it:
- 20 cards out of the 25 action cards are a pop card, with a branching factor of 1
- 5 cards out of the 25 action cards are a recover card, with a branching factor <=4
So an upper bound for the branching factor is 20/25 * 1 + 5/25 * 4 = 0.8 + 4*0.2 = 1.6
Finally, we can simulate it: every time we’ll pick a card in a game, we’ll count of many branches are possible.
We will do so in many games:
python3 gen_branching_factor.py --nb_iterations 10000
1.2827724636190512
With 10000 iterations, the number we find is 1.28.
That’s very low ; in chess, the branching factor is around 30 on average. That’s the source of complains in the review: there is not a lot of choice for the adult :(
That being said, even with a shallow branching factor but with exceptionally long games, many games are possible:
>>> 1.28 ** 100
52601359015.48384
It’s hard to explore all the branches.
Calculating the winning odds
We’ll run many random games against in a classic Monte Carlo fashion, but this time we’ll look at:
- what hands were played
- who was the winner: the player that did not pop all its balloons.
Enumerating the various hands
The 25 balloon cards: there are 5 balloons for each of the 5 different colors:

With this, the hands of 5 cards follow a structure that I’ll use during the rest of this article. They can be one of those:
- 11111
- 2111
- 311
- 41
- 5
- 221
- 32
where:
- 5 means 5 cards of the same color
- 32 means “3 cards of a color, and 2 cards of a different color”,
- 11111 means that the five cards all have a different color
In the sample initial state above, even though we did not sort the cards, we have seen a game “311 vs. 2111”.
Probabilities of encountering those hands
It turns out we can enumerate all the hands. I did this through Monte Carlo At first. It’s not very difficult to list all the seven different structures’ hands. So if we pick five random cards, here are the odds that they’ll follow a given configuration:
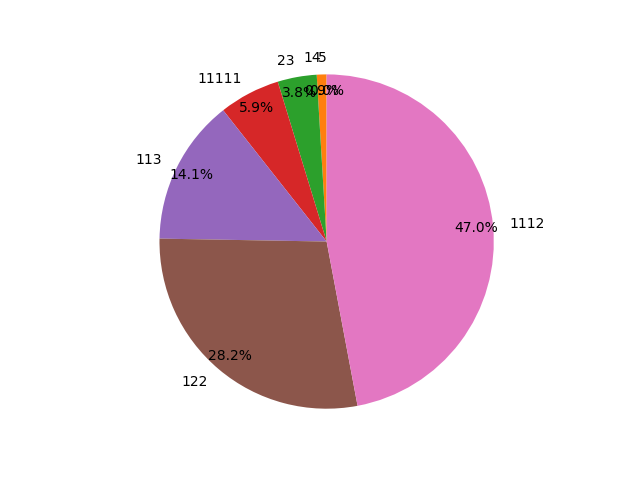
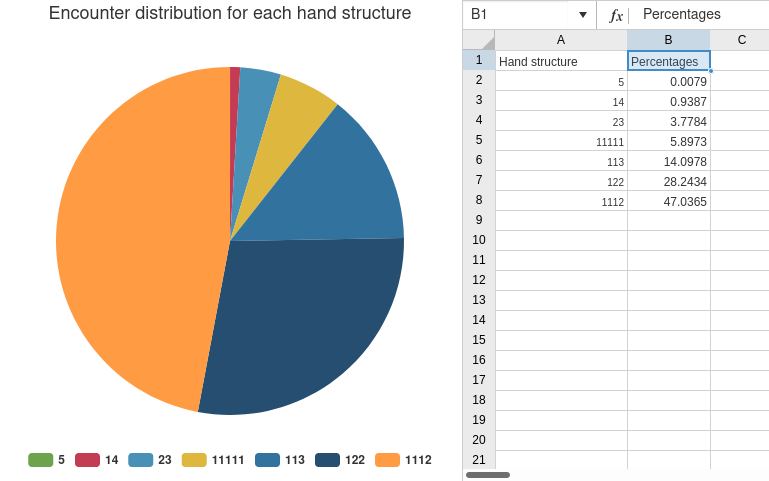
The 5s and the 14s overlap, so its hard to read:
- 5: 0.0079%
- 14: 0.9387%
- 23: 3.7784%
- 11111: 5.8973%
- 113: 14.0978%
- 122: 28.2434%
- 1112: 47.0365%
Some conclusions:
- 47% of the hands are 1112
- 96% of the hands are 1112, 122, 113 or 11111
- 5 are very infrequent.
Computing the odds of winning
I ran, again, many monte carlo games.
With pure random cards
At first, I picked 2 random hands during a given number of iterations, then ran a game for this encounter.
time python3 gen_hand_heatmap.py -p 5 -b 5 -i 10000000
…
real 9m57,285s
The problem with this approach is that we’ve seen some hands are very infrequent, and it was tough to have good numbers for some encounters.
Here is a more visual translation of this problem, through a heatmap, with all the games after the 10000000 iterations :
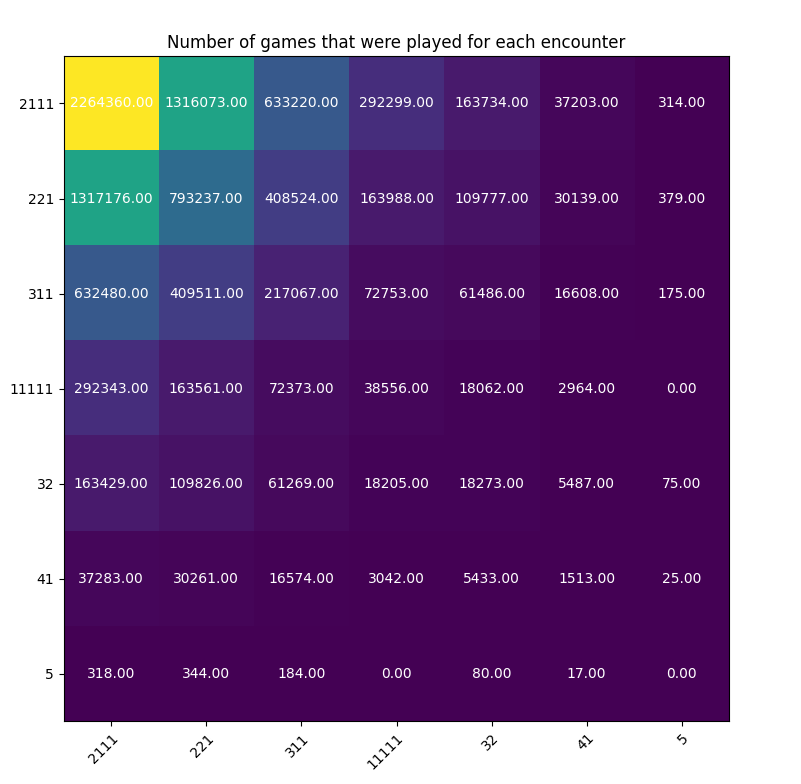
We can see that there were:
- 2264360 games of 1112 vs 1112.
- 17 games of 5 vs 14
- 0 games of 5 vs 5
Those numbers are about what the theory suggests:
- P(picking 1112) = 0.47
- P(picking 1112 / you already picked 1112) = 0.47*0.47 = 0.220
0.22 * 10000000 games = 2200000 games, which is more or less what we found during the simulation (2264360 games of 1112 vs 1112).
We can derive those numbers for the other examples in the same manner.
So if we go for a purely random approach, we have a problem:
- it could be tough to simulate some infrequent kind of encounters
- the frequent encounters will have very high precision, while infrequent games will have a low accuracy: we won’t be able to “trust” all the numbers in the same way.
Uniform distribution of the encounters
A solution to those two problems? We will generate all the hands for each of the seven structures, then generate all the possible encounters for the 7x7 possible hand structure pairs.
I wrote a short utility. It turns out there are not that many hands for each structure:
$ time python3 gen_every_hands.py
11111 1
5 5
41 20
32 20
311 60
221 60
2111 120
In total, that’s 286 different hands.
- the list of all the hands for every kind is here.
- the list of all the encounters is here
So now, for each pairs of structures, we will run many iterations of games with two hands picked randomly in the encounter list we generated. By doing so, we can have a completely uniform distribution of the games played. All the probabilities we will have in the end will have the same level of trust, no matter how rare the encounter is.
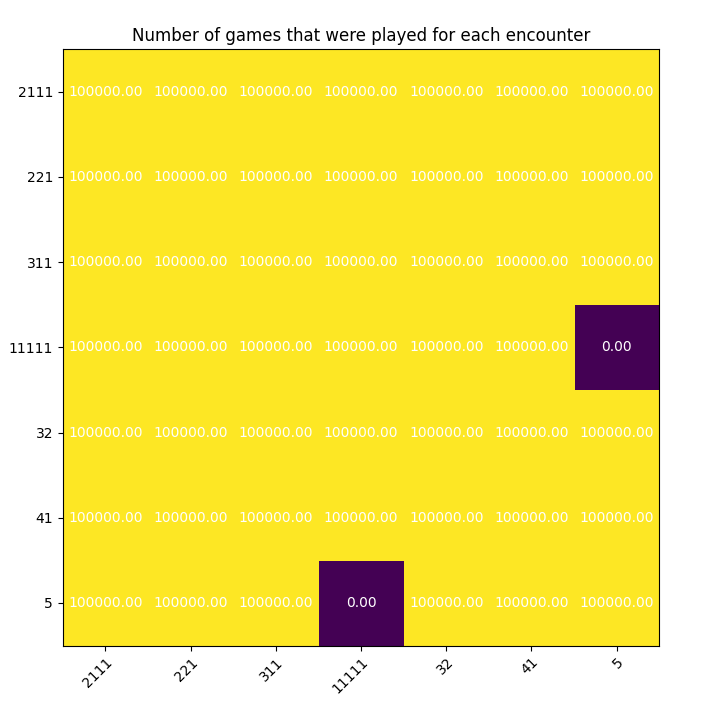
We can also notice that some games are impossible: with a standard deck, it is impossible to deal a 5 vs. 11111.
Now, we can simulate the games and plot the winning rates for each kind of encounter:
time python3 gen_hand_heatmap_uniform.py --nb_iterations 100000
…
real 4m42,866s
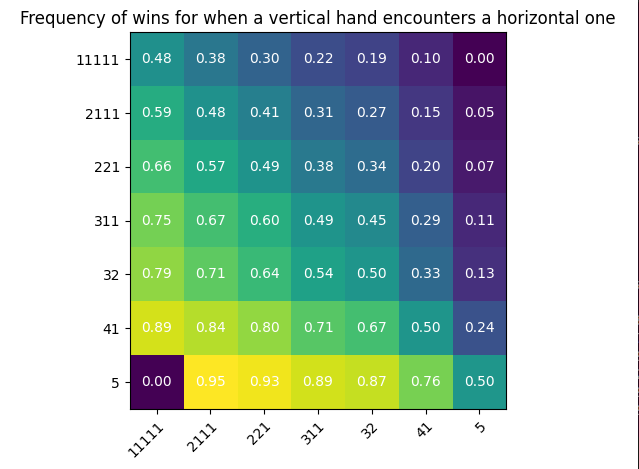
Many things to say already:
- the diagonal is about 50%: a hand against the same hand is about one chance out of two of winning.
- usually, the less frequent the hand is, the more likely it is to win
- this is not true for 11111. Having short runs of the same colors seem to be a disadvantage.
- 5 is the best hand structure. We can explain this with the five parent cards shared between the two players: it yields a strong staying power.
Improving my odds against my kid
Ok, so here we are: we can simulate many games with two players who play randomly, and we can estimate the winning odds when two hands face each other.
It’s time to simulate the same thing, but we will change the strategy for one player (ours). Can we crush him ? Again, the only strategy we need is how to choose which to recover. There are many possible strategies, like:
- always play the first card you dismissed
- if you dismissed a red card, recover it, otherwise pick randomly
Those do not look promising though: we want to improve our odds. There is something we can use: deck knowledge.
We can count the remaining cards in the action deck for each color. When you have to choose which color to recover, we will choose the least available in the rest of the action deck.
The idea for this heuristic is that, in the long run, the card we will recover is less likely than the others to be popped again.
Let’s simulate many games for this heuristic:
python3 gen_hand_heatmap_uniform_with_counter.py -i 100000
Then, I put the result in a heatmap:
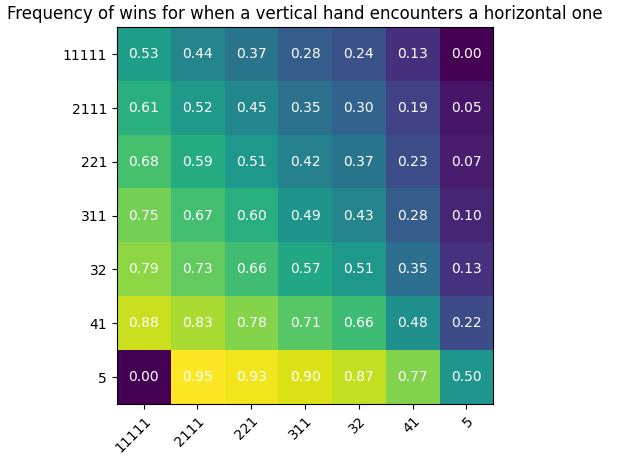
That’s a bit hard to read. Did we improve? Let’s compute the difference between the last two charts to see how much we improved:
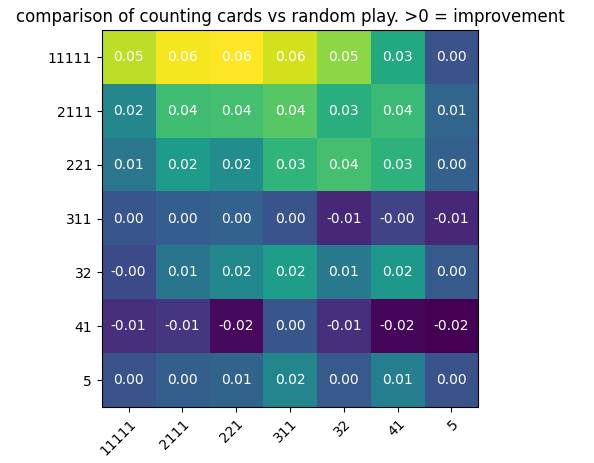
That a small improvement for 11111 and 2111, but that’s an improvement anyway! Given the low branching factor and the high randomness, we couldn’t expect a considerable improvement regardless.
note: substracting two imprecise numbers increases the imprecision. I never properly quantified the error margin, so I would’nt put too much trust on those numbers.
We did it! Concluding thoughts
- if you have a 11111 or 2111, you can squeeze between 1 and 6% more chances to win by counting the remaining cards (only count your colors), then when you have the choice, pick the least probable.
- if you have a 221, 311, or 32, don’t bother counting; your odds won’t improve much
- if you have a 41, counting will hurt you, but the odds are you’ll encounter a winnable hand anyway with the random strategy
- if you have a 5, your branching factor is one no matter what, but you’ll win most of the time
Now you know how to play against your 3yo ;)
Ok, so that was a very complicated way to prove my point: it is possible to improve your odds (here, only or certain configurations) with a simple heuristic, and to quantify the improvement.
Anyway, down the road we’ve learn a bunch of things about game theory, so that’s a net win.
Going further
That was fun but I’ve already spent way too much time with this game. Here are some ideas if you think this is a serious project that deserves some more research:
- you can probably devise a better heuristic
- it’s possible to prune the encounter list a bit more. E.g.
red/red/red/blue/bluevs.yellow/yellow/yellow/green/purpleis one permutation away fromyellow/yellow/yellow/blue/bluevs.red/red/red/green/purple, which asymptotically have the same odds. - I wanted a simple heuristic, but the trend now is to feed every problem to a neural network. Maybe you could try that?
- Go for full tree search, it might be possible. If not, MCTS might help